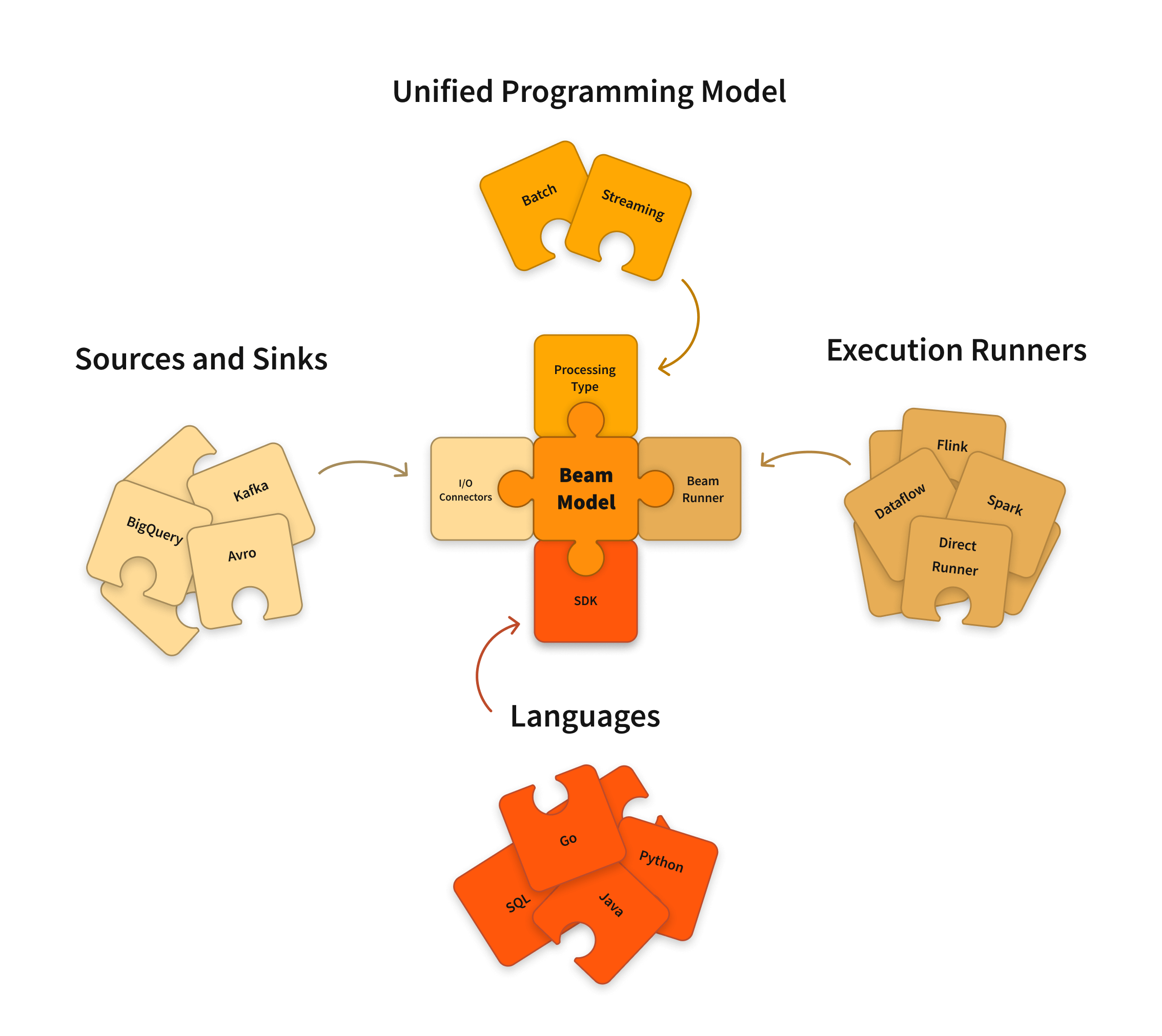
Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Flink, Apache Spark, and Google Cloud Dataflow.
Beam is particularly useful for embarrassingly parallel data processing tasks, in which the problem can be decomposed into many smaller bundles of data that can be processed independently and in parallel. You can also use Beam for Extract, Transform, and Load (ETL) tasks and pure data integration. These tasks are useful for moving data between different storage media and data sources, transforming data into a more desirable format, or loading data onto a new system.
The Beam SDKs provide a unified programming model that can represent and transform data sets of any size, whether the input is a finite data set from a batch data source, or an infinite data set from a streaming data source. The Beam SDKs use the same classes to represent both bounded and unbounded data, and the same transforms to operate on that data. You use the Beam SDK of your choice to build a program that defines your data processing pipeline.
Beam currently supports the following language-specific SDKs: